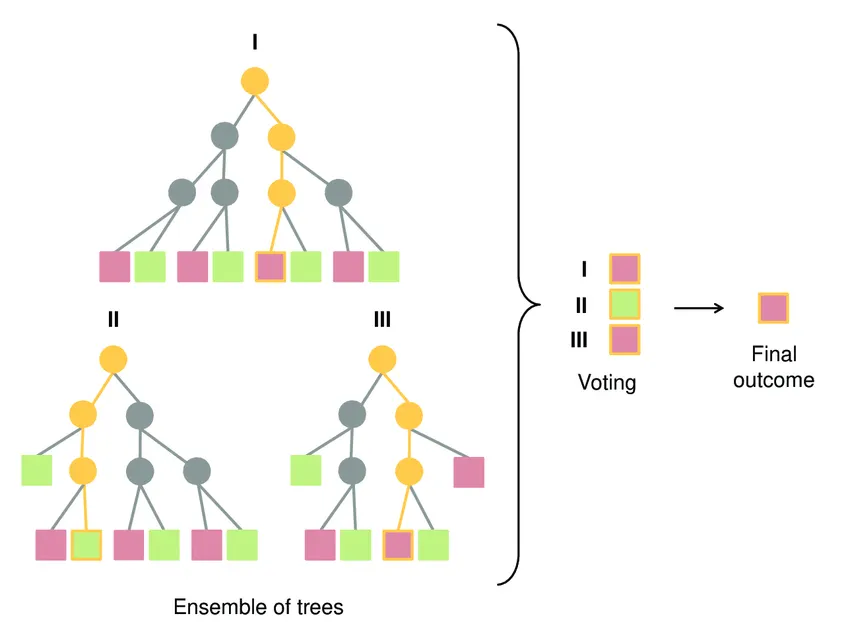
Decision Tree Ensemble Model. Image source; Medium
Checkout the related product Archon on the MQL5 Marketplace for a free demo
In our previous post, we explored Deep Learning and it's applications in AI forex Trading. Yet, in the high-stakes world of algorithmic trading, a quiet revolution has occurred. While the media buzzes about "Deep Learning" and neural networks mimicking the human brain, the professional quantitative finance community has largely doubled down on a different, more pragmatic champion: Tree-Based Ensembles.
Between 2004 and 2015, global interest in AI for Forex was negligible. However, search data reveals a parabolic spike beginning in 2023, culminating in late 2025 where the index for "AI Forex Trading" hit its maximum value.
But why "trees" instead of "brains"? And how does this relate to robust systems like Archon? Let’s decode the architecture of modern Forex prediction, translating the complex math into the logic that drives profit.
The Problem: Noise vs. Signal
To understand why we use these models, you must understand the Bias-Variance Trade-off.
- •
High Bias (Underfitting): A model is too simple (like a moving average). It misses the nuances of the market.
- •
High Variance (Overfitting): A model is too sensitive. It memorizes the noise—like a panic-induced price spike during a news event—and mistakes it for a permanent pattern.
Single Decision Trees are naturally high-variance. They tend to panic. To fix this, we need Ensemble Learning—combining multiple weak models to build one strong "brain."
1. Random Forest: The Stabilizer
The first line of defense is the Random Forest. It uses a technique called Bagging (Bootstrap Aggregating) to create a "forest" of uncorrelated trees.
Imagine you have one historical dataset . If you train one tree on it, it overfits. Bagging solves this by generating new datasets () by sampling uniformly from the original data with replacement. Mathematically, the probability of picking a specific training sample is:
Where is the total number of data points.
Crucially, Random Forest adds Feature Randomness. At every decision node (e.g., "Is RSI > 70?"), the tree is only allowed to look at a random subset of indicators. This prevents a single dominant indicator from dictating the entire strategy, forcing the model to find diverse patterns. The final prediction is the average of all trees, smoothing out the noise:
Research on currency pairs has shown that this approach consistently outperforms traditional linear models by avoiding overfitting in volatile markets9.
2. Gradient Boosting and XGBoost: The Engine of Archon
While Random Forest relies on "democracy" (averaging votes), Gradient Boosting relies on "correction." It builds trees sequentially: Tree 2 fixes the errors of Tree 1, Tree 3 fixes the errors of Tree 2, and so on.
This brings us to XGBoost (Extreme Gradient Boosting), the architecture that powers the core of our Archon trading system.
XGBoost is favored by quants because it balances accuracy with a strict mathematical penalty for complexity. It treats training as an optimization problem to minimize a specific objective function at step :
Here, is the loss (error), and is the regularization term. This regularization is the "secret sauce" that prevents the AI from getting tricked by fake-outs. It penalizes the model based on the number of leaves () and the magnitude of the leaf weights ():
If the model tries to create a hyper-complex rule to explain a tiny market anomaly, the term creates a heavy penalty, effectively saying, "This rule is too expensive; discard it".
This rigorous mathematical foundation allows Archon to navigate high-frequency volatility without breaking. You can read more about our specific implementation of this architecture in our deep-dive blog post: Inside Archon: The Architecture of a Multi-Pair Machine Learning Trading System.
Handling "Missing" Market Data
Forex data is often sparse (e.g., gaps during weekends or non-trading hours). XGBoost employs "Sparsity-aware Split Finding," which automatically learns a default direction (left or right branch) for missing values that minimizes loss. This ensures the model doesn't crash or hallucinate when data feeds are imperfect.
3. LightGBM & CatBoost: Speed and Precision
As datasets grow into the millions of rows (tick data), other architectures play a role.
LightGBM prioritizes speed. Unlike traditional trees that grow level-by-level, LightGBM grows "leaf-wise"—it hunts for the leaf with the highest error and splits it immediately. To manage the massive data, it uses GOSS (Gradient-based One-Side Sampling). GOSS keeps all data points with large errors (high gradients) but downsamples the data points that are already well-predicted, multiplying them by a factor to keep the math balanced:
This allows it to train 20x faster than traditional models.
CatBoost, developed by Yandex, addresses a specific Forex problem: Target Leakage. When predicting time-series, standard models sometimes accidentally "peek" into the future during training. CatBoost uses Ordered Boosting and specific permutations to calculate target statistics without this bias. It builds "Symmetric Trees" (oblivious trees), which are structurally constrained and exceptionally fast for execution on trading servers.
4. Support Vector Machines: The Geometric Approach
Finally, for traders focused on distinct directional movements rather than continuous prices, Support Vector Machines (SVM) offer a geometric solution.
SVMs don't "decide"; they "separate." They look for a hyperplane (a boundary) that maximizes the margin between Buyers and Sellers. Since market data is rarely a straight line, SVMs use the Kernel Trick (specifically the Gaussian RBF Kernel) to map data into higher dimensions where patterns become clear.
For regression (predicting specific returns), Support Vector Regression (SVR) uses an -insensitive tube. The model ignores small errors within a tube of width :
This creates a buffer where minor market noise is ignored, and only significant deviations (Support Vectors) influence the model.
The Future is Hybrid
The data from late 2025 is clear: the market has moved on from simple indicators. The "Mainstream adoption of automated ML pipelines" signifies that the most successful systems are hybrids.
By synthesizing the stability of Random Forests, the geometric precision of SVMs, and the regularized power of Gradient Boosting (as seen in Archon), modern traders can achieve a level of statistical confidence that was previously impossible.
If you are ready to stop guessing and start leveraging the mathematical rigor of XGBoost and Gradient Boosting, explore our flagship solution:
- •
Read the Architecture Deep Dive: Inside Archon Blog
- •
Get Archon on MQL5: Archon Product Page
- •
Visit our Official Site: Auron Automations - Archon v3
The search trends don't lie—the future of Forex is algorithmic. Ensure your architecture is built to handle it.
Happy Trading!